This blog is nothing but my notes from Splunk admin training available on Linkedin Learning by Josh Samuelson , System Admin and DevOps Engineer.
This will be a series of 5 blogs :-
1. Understanding Splunk
2. Search
3. Reporting and Dashboard
4. Alerting
5. Practical Splunk

So we use Splunk to monitor machine data and system logs.
What we can do with System Logs of Splunk :
Collect , Search , Reporting , Visualizations and Alerting.
Collect : One of the major benefit of splunk is that , you can collect all of your data . No need to hunt for logs on multiple server and also gives you benefit of cross reference. Tracing issue from App server to Database server.
Search : A powerful way of searching which comes up with simple filtering and basic constraints along with advance Search context
Reporting Visualization and Alerting : Provides you with the functionality of generating simple reports and dashboards . Dashboards are nothing but data abstracted into simple graphs which helps you to understand pattern and reach to the root cause of any issue quickly and easily. Alerting is just setting the thresholds for which you need your team to be alerted which reduces the monitoring efforts.
Few Splunk Commands that is good to have :-
At the location : /opt/splunk/bin
1. ./splunk start :- This command is used to start the splunk tool , at first go you need to read the terms and conditions and provide admin user and password when prompted. ]
2. ./splunk enable boot-start : Configure Splunk Enterprise to start at boot time
3. systemctl enable splunk : The enable command serves for executing the service since the initialization if consists of one or more units or unit instances. This will create a set of symlinks, as encoded in the [Install] sections of the indicated unit files. the system manager configuration is reloaded (in a way equivalent to daemon-reload), in order to ensure the changes are taken into account immediately. ) [SRC : GFG]
Example : sudo systemctl enable name_service.service

You can get the IP on which splunk is hosted using ifconfig , and after that open any browser htttp://<IP on which splunk is being hosted>:8000.


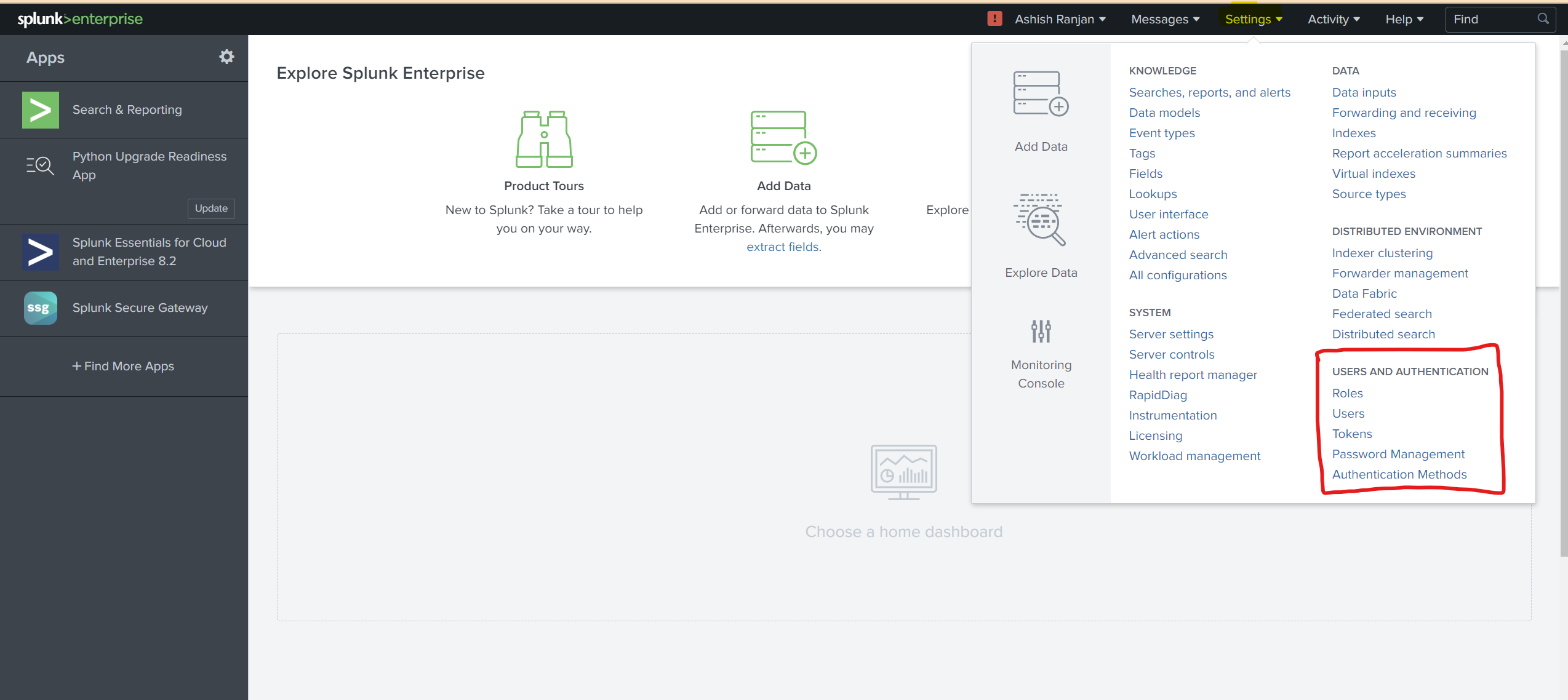
Once you are able to login , you need to go to see the setting and explore the options.
1. Users : will show all the different users that are present in the splunk account at that point of time.

You can see the green button "NEW USER" in which you can add new user :-






Diving in the Report Tab :-

Report tab already has a handful of reports that are used generally , reports is the filtered search data that make some sense and fulfill some agenda.

you are just filtering a search making and adding up time constraint to make some useful monitoring insights.
Connection between Search and Report


Manipulating the report feature :-

It is recommended that you never use the actual report that is initially present you have the option of clone in which you can perform the changes as per the customizations required.
You can clone change the description and title and work on the cloned report.

Edit Options

Edit Schedule

Add-Ons
How to add addons in splunk can be understood in below slides , from adding these you can just utilize features that are their performing a small installation.


Great job for publishing such a nice article. Your article isn’t only useful but it is additionally really informative. Thank you because you have been willing to share information with us.
ReplyDeleteReview Monitoring Services